《PaLM 2 Technical Report》
摘要
We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM (Chowdhery et al., 2022).
我们介绍PaLM 2,这是一款新的最先进的语言模型,具有更好的多语言和推理能力,且比其前身PaLM(Chowdhery等,2022)更加计算效率。
PaLM 2 is a Transformer-based model trained using a mixture of objectives similar to UL2 (Tay et al., 2023).
PaLM 2是一种基于Transformer的模型,使用类似于UL2(Tay等,2023)的目标混合进行训练。
Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM.
通过在英语和多语言语言以及推理任务上进行广泛的评估,我们证明PaLM 2在不同模型大小的下游任务质量方面显著提高,同时展示了比PaLM更快和更高效的推理能力。
This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction.
这种提高的效率使得更广泛的部署成为可能,同时也使模型能够更快地响应,实现更自然的交互节奏。
PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks.
PaLM 2表现出强大的推理能力,在BIG-Bench和其他推理任务上相比PaLM有了显著的改进。
PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities.
PaLM 2在一系列负责任的AI评估中展现出稳定的性能,并能在推理时对有害内容进行控制,而不需要额外的开销或对其他能力产生影响。
Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities.
总体而言,PaLM 2在各种任务和能力方面均达到了最先进的表现。
1 介绍
Language modeling has long been an important research area since Shannon (1951) estimated the information in language with next word prediction.
语言建模一直是一个重要的研究领域,自从Shannon(1951)用下一个词预测估计了语言的信息以来,人们就一直在进行建模研究。
Modeling began with n-gram based approaches (Kneser & Ney, 1995) but rapidly advanced with LSTMs (Hochreiter & Schmidhuber, 1997; Graves, 2014). Later work showed that language modelling also led to language understanding (Dai & Le, 2015). With increased scale and the Transformer architecture (Vaswani et al., 2017), large language models (LLMs) have shown strong performance in language understanding and generation capabilities over the last few years, leading to breakthrough performance in reasoning, math, science, and language tasks (Howard & Ruder, 2018; Brown et al., 2020; Du et al., 2022; Chowdhery et al., 2022; Rae et al., 2021; Lewkowycz et al., 2022; Tay et al., 2023; OpenAI, 2023b). Key factors in these advances have been scaling up model size (Brown et al., 2020; Rae et al., 2021) and the amount of data (Hoffmann et al., 2022).
建模始于基于n-gram的方法(Kneser和Ney,1995),但随后迅速发展成LSTMs(Hochreiter和Schmidhuber,1997;Graves,2014)。后来的研究表明,语言建模也导致了语言理解(Dai和Le,2015)。随着规模的扩大和Transformer架构的出现(Vaswani等人,2017),近几年来大型语言模型(LLMs)在语言理解和生成能力方面表现出了强大的性能,带来了在推理、数学、科学和语言任务方面的突破表现(Howard和Ruder,2018;Brown等人,2020;Du等人,2022;Chowdhery等人,2022;Rae等人,2021;Lewkowycz等人,2022;Tay等人,2023;OpenAI,2023b)。这些进展的关键因素是模型大小的增加(Brown等人,2020;Rae等人,2021)和数据量的增加(Hoffmann等人,2022)。
To date, most LLMs follow a standard recipe of mostly monolingual corpora with a Language modeling objective.
到目前为止,大多数的大型语言模型都采用了标准的配方,即以单一语言的文集为主,并以语言建模为目标。
We introduce PaLM 2, the successor to PaLM (Chowdhery et al., 2022), a language model unifying modeling advances, data improvements, and scaling insights. PaLM 2 incorporates the following diverse set of research advances:
我们介绍PaLM 2,它是PaLM(Chowdhery等人,2022)的继任者,是一种语言模型,汇集了建模进展、数据改进和扩展洞察。PaLM 2结合了以下多样化的研究进展:
• Compute-optimal scaling: 计算优化比例
- Recently, compute-optimal scaling (Hoffmann et al., 2022) showed that data size is at least as important as model size. 最近,计算优化比例(Hoffmann等人,2022)的研究显示,数据大小至少与模型大小同等重要。
- We validate this study for larger amounts of compute and similarly find that data and model size should be scaled roughly 1:1 to achieve the best performance for a given amount of training compute (as opposed to past trends, which scaled the model 3× faster than the dataset).
- 我们对更大的计算量进行了验证,并发现为了达到给定训练计算量的最佳性能,数据和模型大小应大致按1:1的比例进行扩展(与过去的趋势不同,过去的趋势是模型的扩展速度是数据集的3倍)。
• Improved dataset mixtures: 数据集混合改进
- Previous large pre-trained language models typically used a dataset dominated by English text (e.g., ∼78% of non-code in Chowdhery et al. (2022)). 之前的大型预训练语言模型通常使用以英语文本为主导的数据集(例如Chowdhery等人2022年的非代码约占78%)。
- We designed a more multilingual and diverse pre-training mixture, which extends across hundreds of languages and domains (e.g., programming languages, mathematics, and parallel multilingual documents). 我们设计了一种更多语言和多样化的预训练混合数据集,覆盖了数百种语言和领域(例如编程语言、数学和平行多语言文档)。
- We show that larger models can handle more disparate non-English datasets without causing a drop in English language understanding performance, and apply deduplication to reduce memorization (Lee et al., 2021) 我们证明,较大的模型可以处理更多不同的非英语数据集,而且不会使英语语言理解表现下降,同时应用去重技术以减少记忆(Lee等人,2021年)。
• Architectural and objective improvements: 架构和客观改进
- Our model architecture is based on the Transformer. 我们的模型架构基于Transformer。
- Past LLMs have almost exclusively used a single causal or masked language modeling objective. 过去的LLM几乎仅使用单个因果或掩码语言建模目标。
- Given the strong results of UL2 (Tay et al., 2023), we use a tuned mixture of different pre-training objectives in this model to train the model to understand different aspects of language. 鉴于UL2(Tay等人,2023)的强大结果,我们在此模型中使用调整的混合预训练目标,以训练模型了解语言的不同方面。
The largest model in the PaLM 2 family, PaLM 2-L, is significantly smaller than the largest PaLM model but uses more training compute.
PaLM 2家族中最大的模型PaLM 2-L比最大的PaLM模型小得多,但需要更多的训练计算。
Our evaluation results show that PaLM 2 models significantly outperform PaLM on a variety of tasks, including natural language generation, translation, and reasoning.
我们的评估结果显示,PaLM 2模型在自然语言生成、翻译和推理等各种任务上显著优于PaLM。
These results suggest that model scaling is not the only way to improve performance. Instead, performance can be unlocked by meticulous data selection and efficient architecture/objectives.
这些结果表明,模型扩展不是改进性能的唯一途径。相反,通过精心选择数据和高效的架构/目标可以发挥性能。
Moreover, a smaller but higher quality model significantly improves inference efficiency, reduces serving cost, and enables the model’s downstream application for more applications and users.
此外,更小但更高质量的模型可以显著提高推理效率,降低服务成本,并使模型的下游应用适用于更多的应用和用户。
PaLM 2 demonstrates significant multilingual language, code generation and reasoning abilities, which we illustrate in Figures 2 and 3.
PaLM 2展示了显著的多语言能力、代码生成和推理能力,我们在图2和图3中进行了说明。
More examples can be found in Appendix B.1 PaLM 2 performs significantly better than PaLM on real-world advanced language proficiency exams and passes exams in all evaluated languages (see Figure 1).
更多的例子可以在附录B.1中找到。PaLM 2在真实的高级语言能力考试中表现优异,并在所有评估语言中通过了考试(见图1)。
For some exams, this is a level of language proficiency sufficient to teach that language. In this report, generated samples and measured metrics are from the model itself without any external augmentations such as Google Search or Translate.
对于某些考试来说,这是足以教授该语言的语言能力水平。在本报告中,生成的样本和测量的指标都来自于模型本身,没有使用任何外部增强,比如Google搜索或翻译。
PaLM 2 includes control tokens to enable inference-time control over toxicity, modifying only a fraction of pre-training as compared to prior work (Korbak et al., 2023).
PaLM 2 包含控制令牌,使得在推理时可以对毒性进行控制,相对于以前的作品(Korbak et al.,2023),只修改了一小部分预训练。
Special ‘canary’ token sequences were injected into PaLM 2 pretraining data to enable improved measures of memorization across languages (Carlini et al., 2019, 2021).
特殊的“金丝雀”令牌序列被注入到 PaLM 2 的预训练数据中,以提高跨语言记忆的度量方法 (Carlini et al., 2019, 2021)。
We find that PaLM 2 has lower average rates of verbatim memorization than PaLM, and for tail languages we observe that memorization rates increase above English only when data is repeated several times across documents.
我们发现,与 PaLM 相比,PaLM 2 的平均照抄记忆率更低,对于尾部语言,我们观察到只有当数据在多个文档中重复出现数次时,记忆率才会超过英语。
We show that PaLM 2 has improved multilingual toxicity classification capabilities, and evaluate potential harms and biases across a range of potential downstream uses.
我们展示了 PaLM 2 具有改进的多语言毒性分类能力,并评估了潜在的下游使用中的伤害和偏见。
We also include an analysis of the representation of people in pre-training data.
我们还分析了预训练数据中人们的表现。
These sections help downstream developers assess potential harms in their specific application contexts (Shelby et al., 2023), so that they can prioritize additional procedural and technical safeguards earlier in development.
这些部分有助于下游开发人员在特定应用场景中评估潜在的伤害,以便他们能够在开发早期优先考虑额外的程序和技术保障 (Shelby et al.,2023)。
The rest of this report focuses on describing the considerations that went into designing PaLM 2 and evaluating its capabilities.
本报告的其余部分重点介绍设计 PaLM 2 的考虑因素和评估其能力。
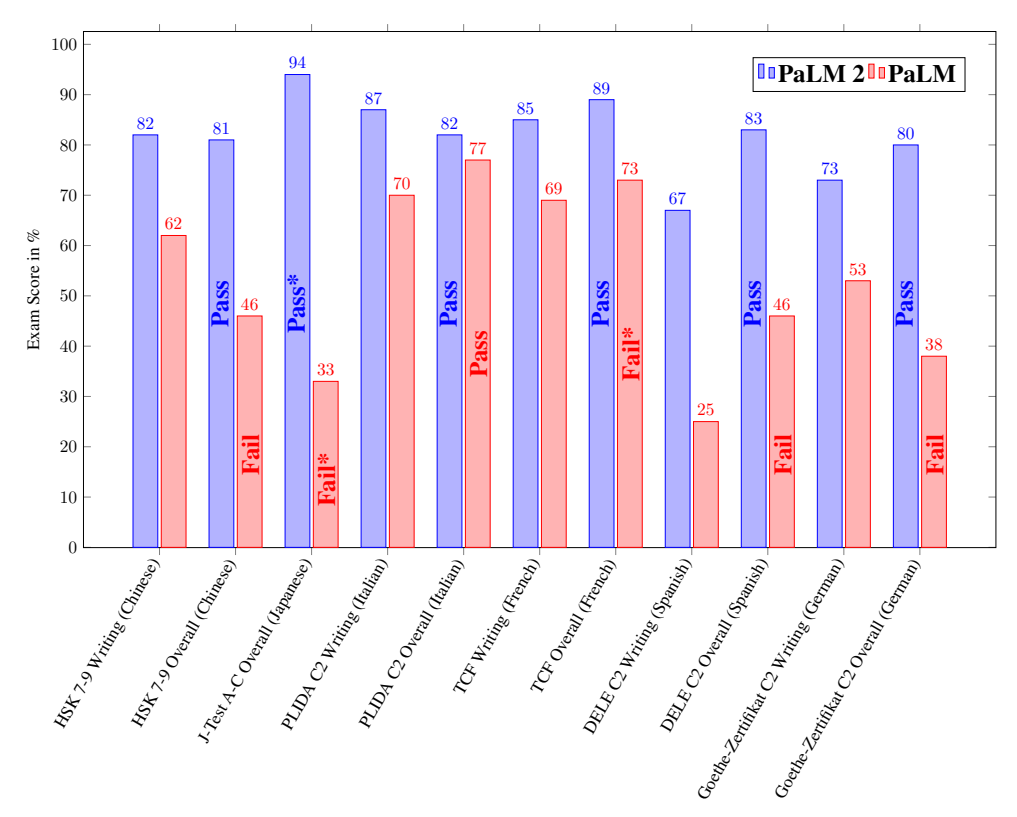
Figure 1: Performance of PaLM 2 and PaLM on the latest available professional language proficiency exams. 图1:PaLM 2和PaLM在最新的专业语言能力考试中的表现。
We used exams for each language to test a C2 (mastery or advanced professional) level proficiency following the CEFR definition. 我们使用每种语言的考试来测试CEFR定义下的C2(掌握或高级职业)水平的熟练程度。
We used the transcripts of the listening portion of the exams and treated them as additional reading questions. 我们使用听力部分的转录作为额外的阅读问题。
We used the most recent year’s exam where available, otherwise we used practice exams representative of the full exam. 我们使用最新年度的考试,否则我们使用代表完整考试的实践考试。
Each writing exam was scored by three professional native speakers. 每篇写作考试由三位专业的母语人士评分。
The writing portion was given equal weight to the final score compared to the non-written portion. 写作部分与非写作部分的最终得分相同。
These were done under simulated conditions and are not official results. 这些是在模拟条件下完成的,不是正式结果。
For more details, see Section 4.1 of this report. * PaLM 2 reached level A/special A on Japanese, whereas PaLM reached level F. PaLM 2 reached level C1 on French. 有关详细信息,请参阅本报告的4.1部分。* PaLM 2在日语方面达到了A / 特A级水平,而PaLM则达到了F级。PaLM 2在法语方面达到了C1级。
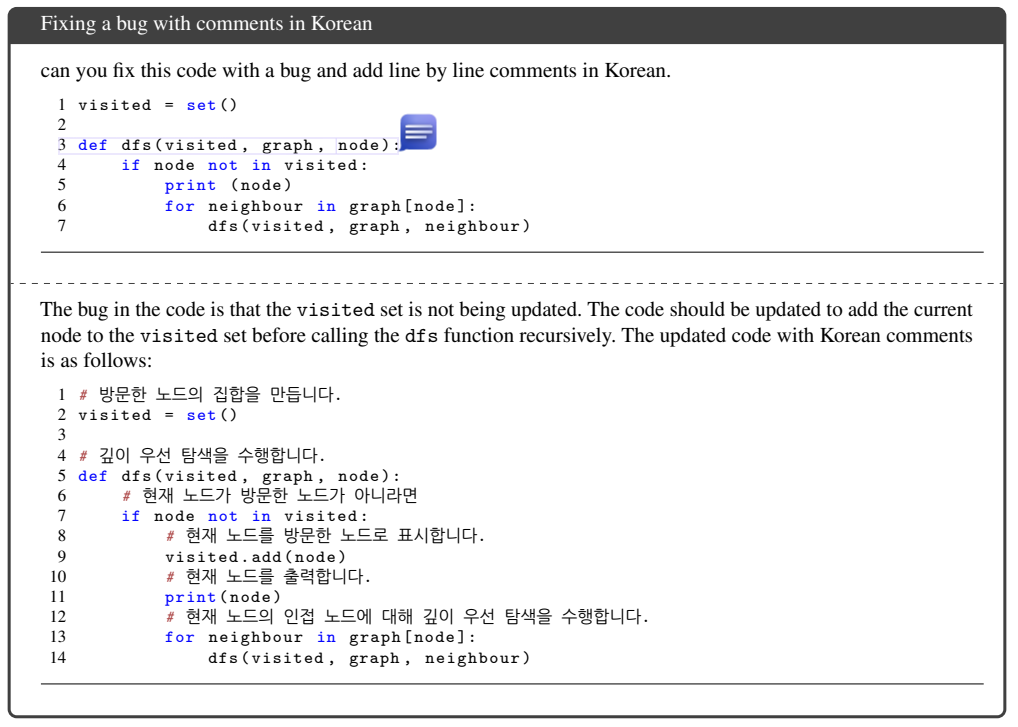
Figure 2: Example of fixing a bug with line-by-line comments in Korean. 图2:用逐行注释修复缺陷的韩语示例。

Figure 3: Describing the meaning of a transliterated Persian proverb and its equivalent in several other languages. 描述一个转写的波斯谚语及其在几种其他语言中的等效意义。
The Persian proverb is an equivalent of "No Pain, No Gain" in English. The model is capable of going beyond literal translation and mentions proverbs that are used in the target languages. 该波斯谚语相当于英语中的“没有付出就没有收获”。该模型能够超越字面翻译,并提及目标语言中使用的谚语。
2 Scaling law experiments 2种比例定律实验
Scaling Transformer language models has become a popular way to achieve state-of-the-art performance. 将 Transformer 语言模型进行缩放已成为实现最先进表现的流行方式。
Kaplan et al. (2020) studied the relationship between scaling the amount of training data (D) and model size (N), and reached the empirical conclusion that it follows a power law, with N needing to grow faster than D. Kaplan 等人 (2020) 研究了训练数据量 (D) 和模型大小 (N) 之间的缩放关系,并得出了实证结论,即 N 需要比 D 更快地增长,呈现幂律关系。
Hoffmann et al. (2022) built upon this observation with a similar study that tuned smaller models’ hyperparameters better.
Hoffmann 等人 (2022) 基于这一观察结果进行了类似的研究,并更好地调整了较小模型的超参数。
Their results corroborated Kaplan et al. (2020)’s power law conclusion; however, they arrived at different results regarding the optimal ratios, showing that N and D should instead grow in equal proportions.
他们的结论证实了 Kaplan 等人 (2020) 的幂律法则,但他们得出了与之不同的结论,即 N 和 D 应该按等比例增长。
In this section, we independently derive scaling laws for very large models. We arrive at a similar conclusion as Hoffmann et al. (2022), i.e., D and N should grow in equal proportions. We then explore the effect of scaling lawson downstream metrics.
在这个部分,我们独立推导了大型模型的缩放规律。我们得出了与Hoffmann等人(2022)类似的结论,即D和N应该成等比例增长。然后,我们探讨了缩放规律对下游指标的影响。
Smoothing final validation loss for each model, we perform quadratic fits for each isoFLOPS band (Figure 4). 为了对每个模型的最终验证损失进行平滑处理,我们对每个isoFLOPS范围进行二次拟合(图4)。
The minima of those quadratic fits indicate the projected optimal model sizes (N) for each isoFLOPS band. 这些二次拟合的最小值表示了每个isoFLOPS范围的预期最优模型大小(N)。
The optimal D is derived from the heuristic FLOPs.
最优的D是从启发式FLOPs中推导出来的。
Plotting these optimal Ns and optimal Ds against FLOPs (Figure 5), we find that D and N should grow in equal proportions as the FLOPs budget increases. 将这些最优的N和最优的D绘制成FLOPs的函数图形(图5),我们发现随着FLOPs预算的增加,D和N应该成等比例增长。
This is a strikingly similar conclusion to Hoffmann et al. (2022), despite that study being conducted at a smaller scale, and with a different training mixture. 这与Hoffmann等人(2022)得出的结论非常相似,尽管那项研究规模较小,并使用了不同的训练组合。
We use the scaling laws from Figure 5 to compute the optimal model parameters (D) and training tokens (N) for
We then train several models from 400M to 15B on the same pre-training mixture for up to 1×1022 FLOPs. 然后我们在相同的预训练混合物上训练了几个400M到15B的模型,最多达到
Finally, we compute loss at the three FLOP points for each model. 最后,我们计算了每个模型在三个FLOP点上的损失。
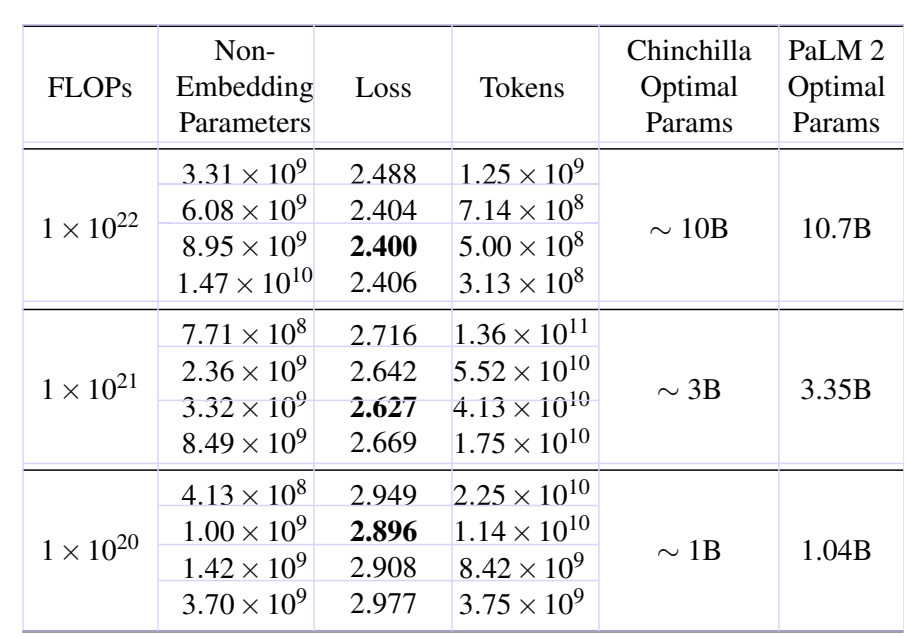
The resulting training losses and their associated optimal model parameters are included in Table 1.
所得到的训练损失及其相关的最佳模型参数在表1中。
We can observe that the lowest loss is achieved by the models that approximately follow the optimal model parameters (D) given the FLOPs. 我们可以观察到,最低的损失是由大约遵循给定的FLOPs的最佳模型参数(D)的模型实现的。
Please note that all the number of parameters mentioned are non-embedding parameters. 请注意,所有提到的参数数量都是非嵌入参数。
2.2 Downstream metric evaluations 下游指标评估
To study the effect of choosing an optimal number of parameters and training tokens given a fixed compute cost of
It is important to note that the selected model sizes, architecture and the training mixture were only used for the study of the scaling laws.
值得注意的是,所选的模型大小、体系结构和训练混合物仅用于研究缩放规律。
We show downstream results of differently-sized models in Table 15 in the Appendix. 我们在附录的表15中展示了不同大小模型的下游结果。
The results suggest that the optimal number of parameters for a model with
However, the training loss is not a perfect proxy for downstream metrics. 然而,训练损失并不是下游指标的完美代理。
For example, the 8.95B model, which shows the lowest loss (Table 1) and is closest to the optimal model, slightly underperforms the 14.7B model on downstream tasks. 例如,8.95B模型(表1中表现最好且最接近最优模型)在下游任务上略逊于14.7B模型。
This suggests that while scaling laws can be used to achieve optimal training loss for a given quantity of FLOPs, this does not necessarily transfer to achieving optimal performance for a given task. 这表明,虽然缩放定律可以用于实现给定FLOPs数量的最佳训练损失,但这不一定转化为实现给定任务的最佳性能。
Moreover, there are several other considerations besides the optimal training loss, such as training throughput and serving latency, which affect the decision regarding the optimal model size. 此外,除了最佳训练损失之外,还有其他考虑因素,例如训练吞吐量和服务延迟,这些因素影响决定最佳模型大小的决策。
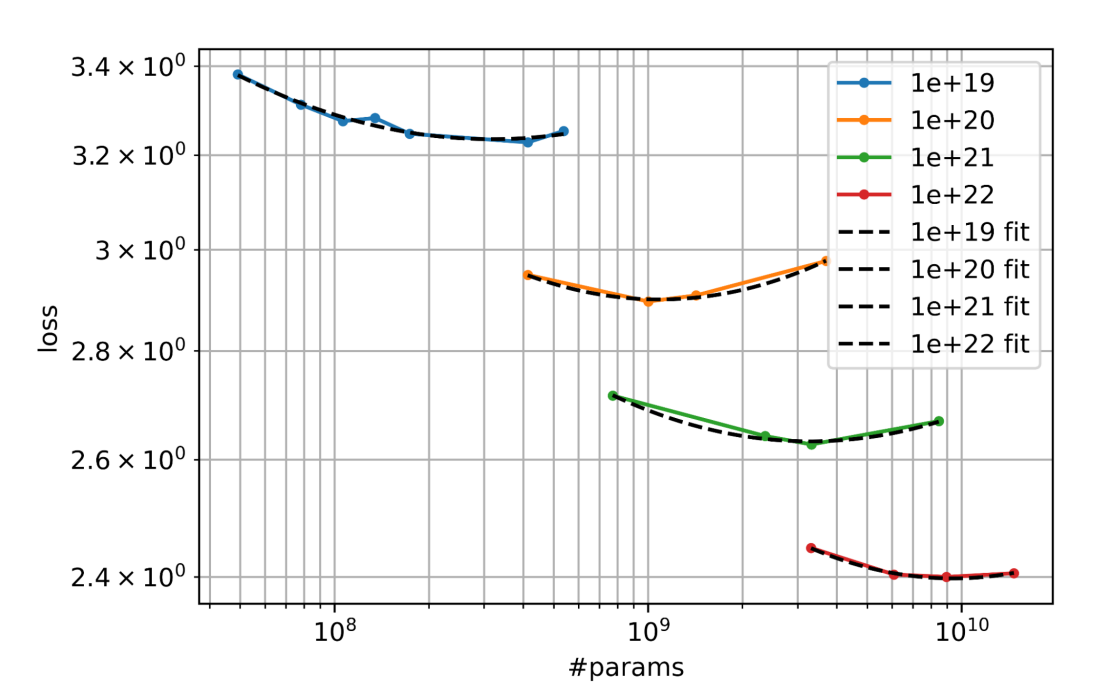
Figure 4: IsoFLOP curves from which we extract the optimal parameters at each compute scale, using a quadratic fit. 图4:我们从中提取每个计算规模的最优参数,使用二次拟合的IsoFLOP曲线。
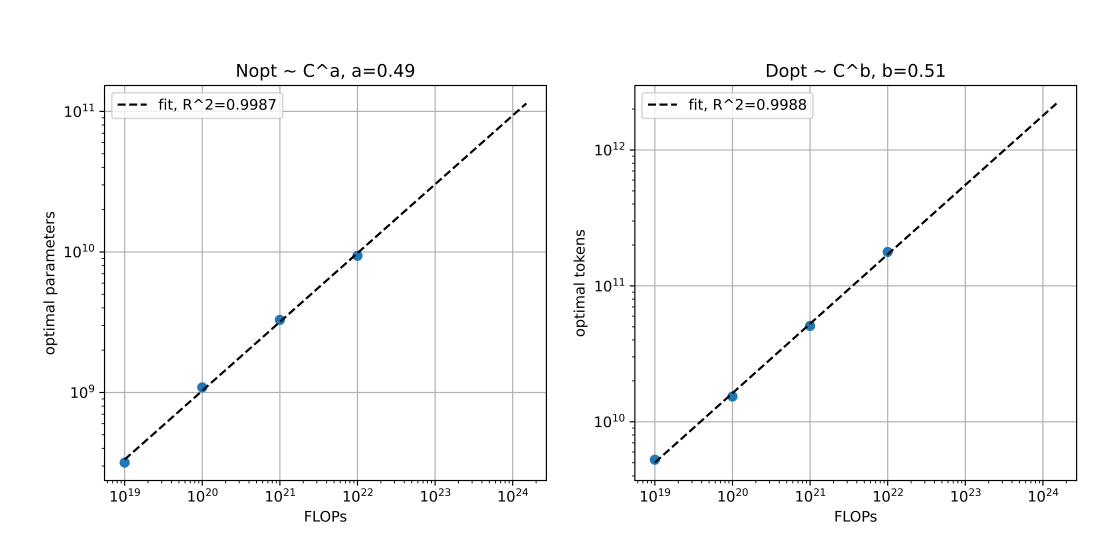
Figure 5: The scaling law obtained from all 4 compute scales. 图5:从所有4个计算规模得出的缩放规律。
Table 1: Estimated optimal parameter size at a given number of FLOPs in our study compared to the study of Hoffmann et al. (2022).
表1:我们研究中在给定的FLOPs数量下估算的最佳参数尺寸,与Hoffmann等人(2022年)的研究进行比较。
3 Training dataset 训练数据集
The PaLM 2 pre-training corpus is composed of a diverse set of sources: web documents, books, code, mathematics, and conversational data.
PaLM 2的预训练语料库由多种来源组成:网络文档、图书、代码、数学和对话数据。
The pre-training corpus is significantly larger than the corpus used to train PaLM (Chowdhery et al., 2022).
预训练语料库比训练PaLM所用的语料库要大得多。
PaLM 2 is trained on a dataset that includes a higher percentage of non-English data than previous large language models, which is beneficial for multilingual tasks (e.g., translation and multilingual question answering), as the model is exposed to a wider variety of languages and cultures.
PaLM 2使用的数据集包含比以前的大型语言模型更高比例的非英语数据,这对于多语言任务(例如,翻译和多语言问答)非常有益,因为模型暴露于更广泛的语言和文化。
This allows the model to learn each language’s nuances.
这使得模型可以学习每种语言的细微差别。
In addition to non-English monolingual data, PaLM 2 is also trained on parallel data covering hundreds of languages in the form of source and target text pairs where one side is in English.
除了非英语单语数据外,PaLM 2 还使用了包括数百种语言的平行数据,其中一边为英语,以源和目标文本对的形式进行训练。
The inclusion of parallel multilingual data further improves the model’s ability to understand and generate multilingual text.
包括平行多语言数据进一步提高了模型理解和生成多语言文本的能力。
It also ingrains an inherent ability to translate into the model, which can be useful for various tasks.
它还赋予了模型翻译的内在能力,这对于各种任务可能是有用的。
Table 21 lists the top 50 languages out of hundreds, with their associated percentages in the multilingual web documents sub corpus.
表 21 列出了数百种语言中排名前 50 的语言以及它们在多语言 Web 文档子语料库中的所占比例。
We did not apply any filtering to explicitly keep or remove any languages.
我们没有对任何语言进行显式保留或去除的过滤。
We employed several data cleaning and quality filtering methods, including de-duplication, removal of sensitive-PII and filtering.
我们采用了几种数据清理和质量过滤方法,包括去重、删除敏感个人身份信息 和过滤。
Even though PaLM 2 has a smaller proportion of English data than PaLM, we still observe significant improvements on English evaluation datasets, as described in Section 4.
即使 PaLM 2 的英语数据比 PaLM 少,我们仍然观察到英语评估数据集的显著改进,如第 4 节所述。
We attribute this partially to the higher data quality in the PaLM 2 mixture.
我们将这部分归因于 PaLM 2 混合中更高的数据质量。
For a small fraction of pre-training data, we added special control tokens marking the toxicity of text, using signals from a fixed version of the Perspective API. 我们在预训练数据的一小部分中添加了特殊的控制标记,标记文本的毒性,使用固定版本的 Perspective API 的信号。
We evaluate the effectiveness of conditioning on control tokens as an inference time control method in Section 5.
我们在第 5 节中评估条件控制标记作为推理时间控制方法的有效性。
Importantly, our evaluations demonstrate that control tokens do not negatively impact performance on unrelated tasks.
重要的是,我们的评估表明,控制标记不会对不相关的任务性能产生负面影响。
We describe special multilingual canaries injected for memorization evaluations in Section 4.7, and conduct a responsible AI-focused analysis of the pre-training data in Appendix E.1.
我们在第 4.7 节中描述了注入用于记忆评估的特殊多语种金丝雀,并在附录 E.1 中进行了预训练数据的负责任的 AI 分析。
PaLM 2 was trained to increase the context length of the model significantly beyond that of PaLM.
PaLM 2训练的目的是将模型的上下文长度显著增加,超过PaLM模型。
This improvement is crucial for enabling capabilities such as long dialog, long-range reasoning and comprehension, summarization, and other tasks that require the model to consider a large amount of context.
这种改进对于实现长对话、远程推理和理解、摘要等任务至关重要,这些任务需要模型考虑大量的上下文。
Our results show that it is possible to increase the context length of the model without hurting its performance on generic benchmarks, which may not require longer contexts.
我们的结果表明,增加模型的上下文长度而不影响其在通用基准测试上的表现是可行的,因为这些测试可能不需要更长的上下文。
4 Evaluation 评估
We evaluate PaLM 2’s performance on exams designed for humans as well as standard academic machine learning benchmarks.
我们评估 PaLM 2在为人类设计的考试以及标准学术机器学习基准测试上的表现。
For exams, we focus on standard language proficiency exams that allow us to assess PaLM 2’s competence in a number of languages.
对于考试,我们关注标准语言熟练度考试,以评估PaLM 2在多种语言下的能力。
On academic benchmarks, we evaluate PaLM 2’s performance on six high-level categories of tasks that exemplify core capabilities and applications of LLMs: classification and question answering, reasoning, coding, translation and natural language generation.
在学术基准测试上,我们评估PaLM 2在六个高级任务类别上的表现,这些任务类别展示了LLM的核心能力和应用:分类和问题回答、推理、编码、翻译和自然语言生成。
Multilinguality and responsible AI considerations are two common threads across all evaluation.
跨语言和负责任的AI考虑是所有评估的两个共同点。
In each section, we employ dedicated datasets to quantify PaLM 2’s multilingual capabilities, and evaluate potential harms and bias.
在每个部分中,我们使用专门的数据集来量化PaLM 2的多语言能力,并评估潜在的危害和偏见。
We additionally describe evaluations of memorization as one aspect of potential privacy harms.
此外,我们还描述了对记忆力的评估作为潜在隐私危害的一个方面。
4.1 Language proficiency exams 语言能力考试
For the human language-proficiency exams, we found a set of exams that corresponded to the highest grade of language proficiency, C2, from the Common European Framework of Reference for Languages (CEFR).
针对人类语言熟练度考试,我们找到了一组与欧洲语言共同参考框架(CEFR)最高语言熟练度等级C2相对应的考试。
This is similar to level S/D under ACTFL or 4/4+ under ILR.
这类似于ACTFL的S/D级别或ILR的4/4+级别。
We performed generic instruction finetuning and did no training that was targeted for these exams.
我们进行了通用指令微调,并没有针对这些考试进行训练。
We found the most recent publicly-available past or practice exams and simulate an exam setting with these models and give an estimated score.
我们找到了最近可公开获得的过去或练习考试,并利用这些模型模拟考试环境并给出预估分数。
Models are prompted with the name of the exam and a question or a set of questions within a block—no few-shot examples are used.
模型将以考试名称和问题或一组问题为提示——不使用少量样本示例。
These exams consist of both multiple-choice and writing questions and we use a set of third-party raters to independently rate the results of the writing exams out of 5 where 5 is the score given to a native adult speaker.
这些考试包括选择题和写作题,我们使用一组第三方评估员独立评估写作考试的结果,得分范围为1-5。
We did not use the speaking part of exams. For listening exams, we used transcripts where available and treated them as additional questions for the reading exam.
我们没有使用考试的口语部分。对于听力考试,我们使用听力稿件,将其视为阅读考试的额外问题。
Finally, we equally weight the reading and writing portions of the exam and assign a score.
最后,我们同等权重考虑阅读和写作部分的考试,并给出一个分数。
We then give a pass/fail result in accordance with official guidelines. Note that these are not official grades. Further details can be found in Appendix C.
然后根据官方指南给出合格或不合格的结果。请注意,这些不是官方成绩。有关更多详细信息,请参见附录C。
We show the results in Figure 1. PaLM 2 outperforms PaLM across all exams and achieves a passing grade for every language, demonstrating language proficiency across all evaluated languages.
我们在图1中展示了结果。PaLM 2在所有考试中表现优异,对于每种语言都获得了及格分数,证明了在所有评估的语言中具有语言能力。
4.2 Classification and question answering 分类和问题回答
Classification and question answering (QA) are established natural language understanding tasks, which have formed a common test bed for the evaluation of large language models.
分类和问题回答(QA)是已建立的自然语言理解任务,已成为评估大型语言模型的常见测试基础。
We assess PaLM 2’s performance on datasets that have been commonly used in the LLM literature (Brown et al., 2020; Du et al., 2022; Chowdhery et al., 2022).
我们评估PaLM 2在LLM文献中常用的数据集上的表现(Brown等人,2020;Du等人,2022;Chowdhery等人,2022)。
We also include tasks that assess PaLM 2’s multilingual capabilities.
我们还包括评估PaLM 2多语言能力的任务。
English QA and classification tasks 英语 QA 和分类任务
We first evaluate the PaLM 2 variants on a set of standard English question answering and classification tasks used in prior work (Du et al., 2022; Brown et al., 2020; Chowdhery et al., 2022), including:
我们首先在一些标准的英语问答和分类任务上评估PaLM 2的变体,这些任务在之前的研究中被使用过(Du等人,2022; Brown等人,2020; Chowdhery等人,2022),包括:
-
Open-domain closed-book question answering tasks: TriviaQA (Joshi et al., 2017), Natural Questions2 (Kwiatkowski et al., 2019), and WebQuestions (Berant et al., 2013)
开放领域的闭卷问答任务:TriviaQA(Joshi等,2017年),自然问题2(Kwiatkowski等,2019年)和WebQuestions(Berant等,2013年)。 -
Cloze and completion tasks: LAMBADA (Paperno et al., 2016), HellaSwag (Zellers et al., 2019), and StoryCloze (Mostafazadeh et al., 2016)
填空和补全任务:LAMBADA(Paperno等,2016),HellaSwag(Zellers等,2019)和StoryCloze(Mostafazadeh等,2016)。 -
Winograd-style tasks: Winograd (Levesque et al., 2012) and WinoGrande (Sakaguchi et al., 2021)
Winograd风格的任务:Winograd(Levesque等人,2012)和WinoGrande(Sakaguchi等人,2021)。 -
Reading comprehension: SQuAD v2 (Rajpurkar et al., 2018) and RACE (Lai et al., 2017)
阅读理解:SQuAD v2(Rajpurkar等人,2018)和RACE(Lai等人,2017) -
Common sense reasoning: PIQA (Bisk et al., 2020), ARC (Clark et al., 2018), and OpenBookQA (Mihaylov et al., 2018)
常识推理:PIQA(Bisk等,2020)、ARC(Clark等,2018)和OpenBookQA(Mihaylov等,2018) -
SuperGLUE (Wang et al., 2019)
SuperGLUE(Wang等,2019年) -
Natural language inference: Adversarial NLI (ANLI; Nie et al., 2020)
自然语言推理:对抗性NLI(ANLI;Nie等人,2020)
Table 2: Evaluation on English QA and classification tasks in a 1-shot setting. Accuracy is reported for all tasks, except when otherwise indicated. Tasks splits are the same as in (Brown et al., 2020; Du et al., 2022; Chowdhery et al., 2022). PaLM results are from Chowdhery et al. (2022).
表2:1-shot场景下英语问答和分类任务的评估。除非另有说明,否则所有任务的准确率都会报告。任务划分与(Brown et al. 2020;Du et al. 2022;Chowdhery et al. 2022)相同。PaLM的结果来自Chowdhery等人(2022年)。
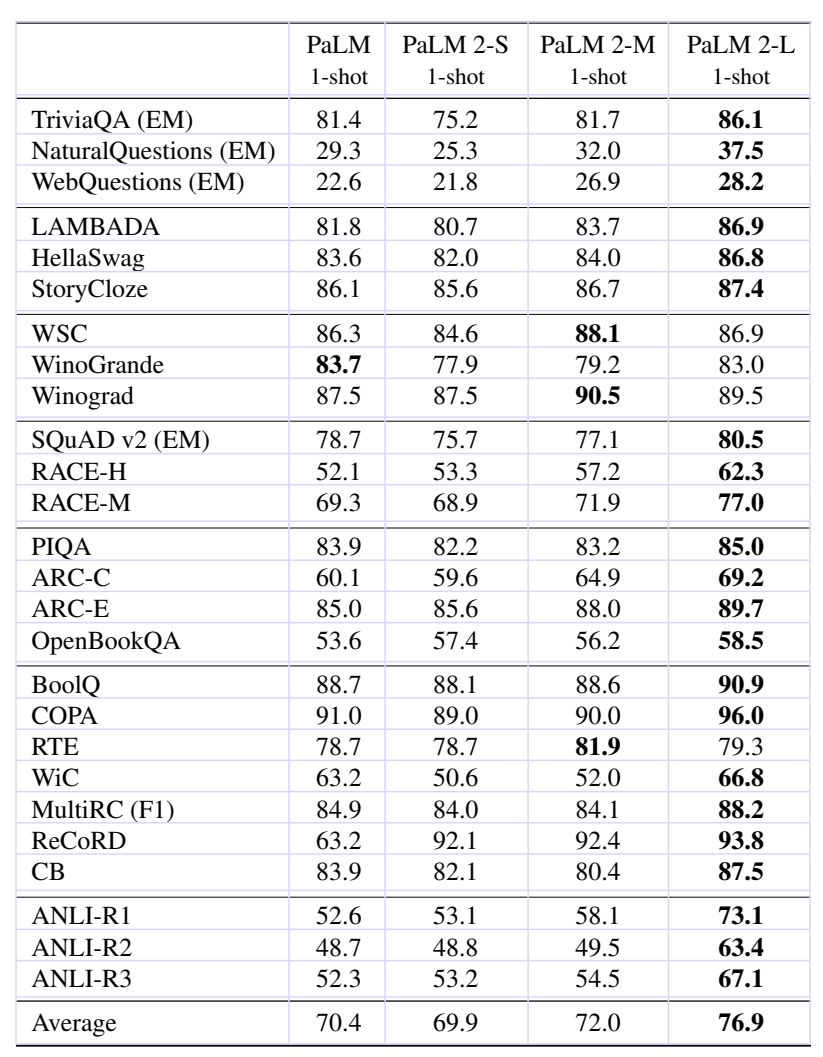
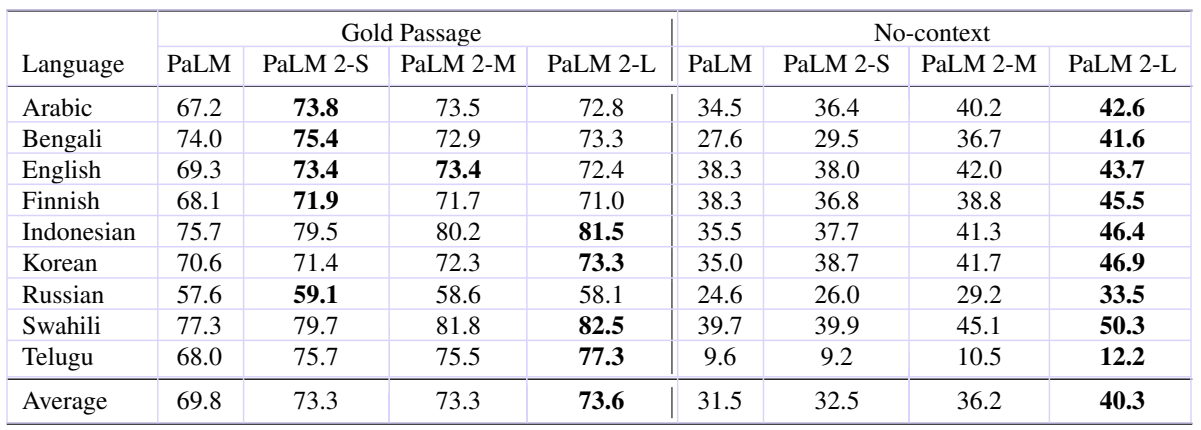
Table 3: F1 scores on the multilingual TyDi QA datasets in a 1-shot setting. We evaluate in the Gold Passage and a novel no-context setting.
表3:在1-shot设置下在多语言TyDi QA数据集中的F1分数。我们在Gold Passage和一个新的无上下文设置中进行评估。
We compare the PaLM 2 variants to PaLM 540B in a one-shot setting, and show results in Table 2.
我们在一次性设置中将 PaLM 2 变体与 PaLM 540B 进行比较,并在表2中展示结果。
We observe that even the smallest PaLM 2 variant achieves performance competitive with the much larger PaLM 540B model while PaLM 2-M already outperforms PaLM consistently. We highlight that PaLM 2-L achieves:
我们观察到即使最小的 PaLM 2 变体也能达到与更大的 PaLM 540B 模型竞争性能,而 PaLM 2-M 已经连续优于 PaLM。我们强调,PaLM 2-L 实现了:
• Large improvements over PaLM across almost all tasks.
在几乎所有任务上,相对于PaLM都有大幅度的改进。
• Similar performance on WSC and WinoGrande, which both employ Winograd schemas.
在WSC和WinoGrande上表现相似,这两个任务都使用了Winograd模式。
- Particularly strong improvements on the Adversarial NLI (ANLI) datasets, where robustness is important, the ReCoRD commonsense reasoning dataset, and the RACE datasets for reading comprehension.
在Adversarial NLI (ANLI)数据集,其中鲁棒性很重要,在ReCoRD常识推理数据集和RACE阅读理解数据集上出现了特别强的改进。
We measure potential bias in QA performance on questions related to identity terms, together with bias in other generative tasks, in Section 4.6.
我们在第4.6节中测量了与身份术语相关的问题的QA表现的潜在偏见,以及其他生成式任务的偏见。
We find that PaLM 2 performs well on disambiguated questions about social identity and do not observe a systematic pattern of bias, with full results in Appendix E.6.
我们发现PaLM 2在有关社会身份的澄清问题上表现良好,并没有观察到一种系统性的偏见模式,具体结果见附录E.6。
Multilingual QA 多语言问答
To demonstrate PaLM 2’s multilingual capabilities, we evaluate on the multilingual QA dataset TyDi QA (Clark et al., 2020) in a one-shot setting.3
为展示PaLM 2的多语言能力,我们在一次性设置下对多语言QA数据集TyDi QA(Clark等人,2020)进行评估。
We additionally propose a more challenging no-context setting where the model has to answer the question solely based on the knowledge stored in its parameters.4 We show the results in Table 3.
我们还提出了一个更具挑战性的无上下文设置,其中模型只能根据其参数中存储的知识来回答问题。我们在表3中展示结果。
Table 4: Toxicity classification AUC-ROC on Multilingual Jigsaw and English Civil Comments.
表格4:多语种拼图和英文公民评论的毒性分类AUC-ROC。
All PaLM 2 variants consistently outperform PaLM across both settings.
所有的PaLM 2变种在两种情况下都始终优于PaLM。
In the Gold Passage setting, differences between PaLM 2 variants are relatively small, indicating that all models have learned robust multilingual reading comprehension.
在Gold Passage情况下,PaLM 2变种之间的差异相对较小,表明所有模型都学习了强大的多语言阅读理解能力。
In the more challenging no-context setting, performance differences across model sizes are more evident.
在更具挑战性的无上下文设置中,不同模型尺寸的性能差异更为明显。
The largest PaLM 2 clearly outperforms all comparison models.
最大的PaLM 2明显优于所有比较模型。
Across both settings, improvements over PaLM are particularly pronounced for languages with limited data, such as Telugu, Swahili, and Indonesian and languages with non-Latin scripts such as Arabic and Korean.
在这两种情况下,对于数据有限的语言(如特鲁古语、斯瓦希里语和印尼语)以及具有非拉丁文字符的语言(如阿拉伯语和韩语),相对于PaLM的改进尤其明显。
Multilingual toxicity classification 多语言毒性分类
We evaluate PaLM 2 on toxicity classification as a representative example of common classification tasks within responsible AI practices.
我们将PaLM 2在毒性分类上进行评估,作为负责任的AI实践中常见分类任务的代表性例子。
Adapting prompting methods from Schick et al. (2021) to zero-shot and few-shot contexts, we find that PaLM 2 improves over PaLM on toxicity classification in English (Borkan et al., 2019) and on non-English examples using the Jigsaw multilingual dataset (Jigsaw, 2019), with slightly reduced performance in Spanish. Detailed results are in Appendix E.4.
我们采用Schick等人(2021)的提示方法来适应零样本和少样本情境,并发现PaLM 2在英语(Borkan等人,2019)上的毒性分类以及使用Jigsaw多语言数据集(Jigsaw,2019)的非英语示例上比PaLM有所提高,但在西班牙语上的性能略有降低。详细结果见附录E.4。
Multilingual capabilities 多语言能力
We provide additional examples of PaLM 2’s multilingual capabilities in Appendix B.1, and evaluation of potential harms and bias in E.3.2.
我们在附录B.1中提供了PaLM 2多语言能力的其他示例,并在E.3.2中评估潜在危害和偏见。
PaLM 2 is able to perform many capabilities such as explaining jokes, generating creative texts, etc. that were limited to English in previous models in many other languages.
PaLM 2能够执行许多功能,例如解释笑话、生成创意文本等,在先前的模型中往往仅限于英语。
In addition, it is able to seamlessly convert between registers, dialects, and scripts of different languages.
此外,它能够无缝地在不同语言的不同语体、方言和书写系统之间转换。
4.3 Reasoning 推理能力
The ability of large models to reason, to combine multiple pieces of information, and to make logical inferences is one of their most important capabilities.
大型模型具有推理、组合多个信息和进行逻辑推断的能力是它们最重要的能力之一。
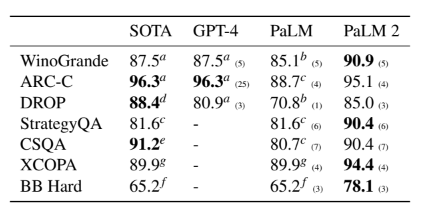
We evaluate PaLM 2’s reasoning capabilities on representative reasoning datasets in a few-shot setting including WinoGrande (Sakaguchi et al., 2021), ARC-C (Clark et al., 2018), DROP (Dua et al., 2019), StrategyQA (Geva et al., 2021), CommonsenseQA (CSQA; Talmor et al., 2019), XCOPA (Ponti et al., 2020), and BIG-Bench (BB) Hard (Suzgun et al., 2022).
我们在少样本实验设置下,在几个代表性的推理数据集(包括WinoGrande、ARC-C、DROP、StrategyQA、CSQA、XCOPA和BIG-Bench)上评估了PaLM 2的推理能力。
We compare to PaLM, GPT-4 (OpenAI, 2023b), and the state of the art (SOTA) for each dataset.5 We employ the instruction-tuned version of PaLM 2 (see Appendix A.2 for the detailed instruction tuning results) except for the multilingual XCOPA dataset.6
我们与PaLM、GPT-4和每个数据集的最新表现(SOTA)进行比较。我们使用了PaLM 2的指令调整版本(请参见附录A.2中的详细指令调整结果),除了多语种XCOPA数据集。
PaLM 2 outperforms PaLM across all datasets and achieves results competitive with GPT-4.
PaLM 2 在所有数据集上表现优于 PaLM,并且在与 GPT-4 相媲美的结果上取得了竞争力。
On the multilingual XCOPA dataset, PaLM 2 achieves particularly strong improvements on under-represented languages such as Swahili, Quechua, and Haitian and establishes a new state of the art even without chain-of-thought prompting (Wei et al., 2022) (see Appendix A.3 for the detailed results).
在多语言 XCOPA 数据集上,PaLM 2 特别在少数语言(如斯瓦西里语、克丘亚语和海地克里奥尔语)上取得了强劲的改进,并且即使不需要链式思维提示,也建立了新的最佳效果(参见附录 A.3 的详细结果)。
On BIG-Bench Hard, PaLM 2 outperforms PaLM on every task, often by a large margin. We discuss improvements on the challenging BIG-Bench Hard tasks below.
在 BIG-Bench Hard 上,PaLM 2 在每个任务上的表现均优于 PaLM,通常差距很大。我们将在以下讨论在具有挑战性的 BIG-Bench Hard 任务上的改进。
Table 5: Evaluation on reasoning tasks. We show the number of exemplars in brackets. PaLM 2 results are using its instruction-tuned variant (see Appendix A.2) except for XCOPA; PaLM 2 results on ARC-C, StrategyQA, and CSQA use chain-of-thought prompting (CoT; Wei et al., 2022) and self-consistency (SC; Wang et al., 2023). PaLM 2 results on BB Hard use CoT. Superscripts denote results from past work: aGPT-4 (OpenAI, 2023b), bPaLM (Chowdhery et al., 2022), cPaLM+CoT+SC (Wang et al., 2023), dQDGAT (Chen et al., 2020), eDeBERTaV3-large+KEAR (Xu et al., 2022), f PaLM+CoT (Suzgun et al., 2022), gPaLM+CoT (Shi et al., 2023).
表格5:推理任务评估。我们在括号中显示了示例数。PaLM 2的结果使用其指令调整版本(请参见附录A.2)。除了XCOPA外,ARC-C、StrategyQA和CSQA上的PaLM 2结果使用思维链提示(CoT;Wei等,2022)和自我一致性(SC;Wang等,2023)。 PaLM 2在BB Hard上使用CoT。上标表示过去工作的结果:aGPT-4(OpenAI,2023b),bPaLM(Chowdhery等,2022),cPaLM+CoT+SC(Wang等,2023),dQDGAT(Chen等,2020),eDeBERTaV3-large+KEAR(Xu等,2022),fPaLM+CoT(Suzgun等,2022),gPaLM+CoT(Shi等,2023)。
The Beyond the Imitation Game Benchmark (BIG-bench; Srivastava et al., 2022) provides a large, collaborative suite of over 200 tasks that can be used to probe LLMs’ performance across a range of fields and capabilities. BIG-Bench Hard (Suzgun et al., 2022) is a subset of 23 BIG-Bench tasks where the best LLMs performed below the average human rater at the time of writing.7
BIG-Bench Hard(Suzgun等人,2022)是BIG-Bench的一个子集,其中最佳的LLM的表现低于目前的平均人类评分者。该子集包括23个任务,可用于探究LLMs在一系列领域和能力方面的表现。
We follow the experimental setup of Suzgun et al. (2022) using both few-shot (direct) prompting and chain-of-thought prompting (Wei et al., 2022).
我们按照Suzgun等人(2022)的实验设置,同时使用few-shot(直接)提示和连续思考提示(Wei等人,2022)。
We use the same 3-shot prompts and take 250 examples per task8to produce a set of 6,511 total examples.
我们使用相同的3-shot提示,并选取每个任务250个示例,产生总计6,511个示例集。
We show the results in Table 6. PaLM 2 achieves large improvements on this challenging set of tasks compared to PaLM.
我们在表6中展示结果。PaLM 2在这一具有挑战性的任务集上相对于PaLM实现了巨大的改进。
On several tasks including solving multi-step arithmetic problems (multistep_arithmetic), reasoning with temporal sequences, answering questions about when certain events occurred (temporal_sequences), and hierarchical reasoning using Dyck languages (dyck_languages) PaLM 2 improves over PaLM by more than 100%, demonstrating new 涌现 abilities.
在多步算术问题的解决(multistep_arithmetic)、对时间序列进行推理、回答一些事件发生的时间(temporal_sequences)以及使用 Dyck 语言进行层次推理(dyck_languages)等多个任务中,PaLM 2的改进超过了100%,展示了新的涌现能力。
Mathematical reasoning LLMs have struggled on tasks that require quantitative reasoning, such as high-school and college-level problems in mathematics, science, and engineering (Hendrycks et al., 2021; Cobbe et al., 2021).
数学推理LLM在需要量化推理的任务上表现不佳,例如高中和大学级别的数学、科学和工程问题(Hendrycks等,2021;Cobbe等,2021)。
Recently, Minerva (Lewkowycz et al., 2022) achieved significant gains on quantitative reasoning tasks by Fine-Tuning PaLM on scientific and mathematical content from the Web.
最近,Minerva(Lewkowycz等,2022)通过对来自Web的科学和数学内容对PaLM进行微调,在量化推理任务上取得了显著进展。
We evaluate PaLM 2 on MATH (Hendrycks et al., 2021), which contains 12,500 problems from high school competitions in 7 mathematics subject areas, GSM8K (Cobbe et al., 2021), a dataset of 8,500 grade school math word problems, and MGSM (Shi et al., 2023), a multilingual version of GSM8K with translations of a subset of examples into ten typologically diverse languages.
我们在数学数据集MATH(Hendrycks等,2021)上评估PaLM 2,该数据集包含来自7个数学学科领域的12500个高中竞赛问题,GSM8K(Cobbe等,2021)是一个包含8500个小学数学问题的数据集,MGSM(Shi等,2023)是GSM8K的多语言版本,其中一部分样例被翻译成十种类型差异明显的语言。
We compare PaLM 2 to PaLM, Minerva (Lewkowycz et al., 2022), GPT-4 (OpenAI, 2023b), and the state of the art for each dataset.
我们将PaLM 2与PaLM、Minerva(Lewkowycz等,2022)、GPT-4(OpenAI,2023b)和每个数据集的最先进方法进行比较。
For MATH, we follow Lewkowycz et al. (2022) and use the same 4-shot chain-of-thought prompt, combined with self-consistency (Wang et al., 2023) utilizing 64 sample paths.
对于数学方面,我们遵循Lewkowycz等人(2022)的方法,采用相同的4-shot思维链提示,结合自洽性(Wang等人,2023)使用64个样本路径。
For GSM8K, we use the same 8-shot chain-of-thought prompt as in (Wei et al., 2022), and self-consistency with 40 sample paths.
对于GSM8K,我们采用与Wei等人(2022)相同的8-shot思维链提示,并使用40个样本路径的自洽性。
We use the SymPy library (Meurer et al., 2017) to compare answers and guard against false negatives, which arise from equivalent answers with different surface forms. For MGSM, we use 8-shot chain-of-thought prompts and in-language exemplars provided by Shi et al. (2023).
我们使用SymPy库(Meurer等人,2017)来比较答案,防止因表面形式不同而产生的误判。对于MGSM,我们使用由Shi等人(2023)提供的8-shot思维链提示和同语言的范例。
We show the results in Table 7. PaLM 2 outperforms PaLM dramatically on all datasets.
我们在表格7中展示了结果。在所有数据集上,PaLM 2的表现都大大优于PaLM。
On MATH, PaLM 2 is competitive with the state-of-the-art performance achieved by the dedicated Minerva model. On GSM8K, PaLM 2 outperforms Minerva and GPT-4 while on MGSM, it surpasses the state of the art even without self-consistency.
在MATH数据集上,PaLM 2与专用的Minerva模型取得了竞争状态下的最佳性能。在GSM8K上,PaLM 2超越了Minerva和GPT-4,而在MGSM上,即使没有考虑自我一致性,它也超越了现有技术的领先地位。
Table 6: BIG-Bench Hard 3-shot results. PaLM and PaLM-2 use direct prediction and chain-of-thought prompting (Wei et al., 2022) following the experimental setting of Suzgun et al. (2022).
表6:BIG-Bench Hard 3-shot结果。PaLM和PaLM-2使用直接预测和思维链提示(Wei等人,2022),遵循Suzgun等人(2022)的实验设置。
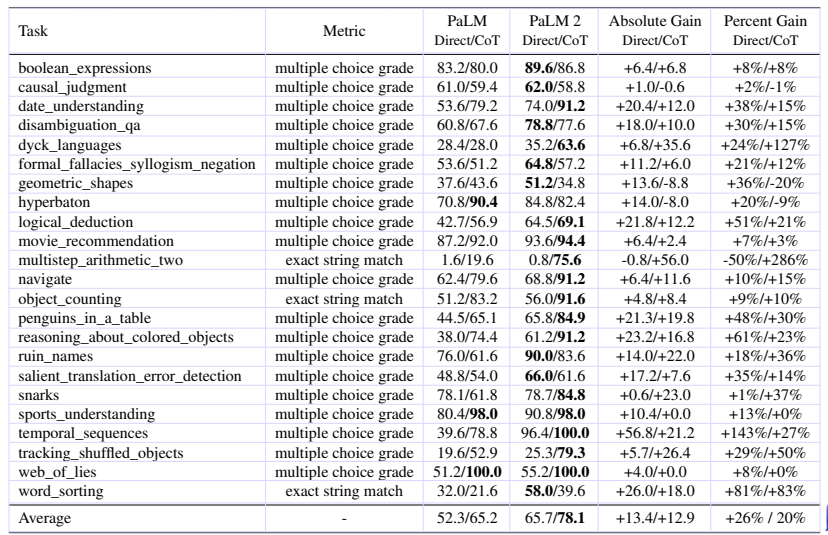
Table 7: Evaluation results on MATH, GSM8K, and MGSM with chain-of-thought prompting (Wei et al., 2022)/ self-consistency (Wang et al., 2023). The PaLM result on MATH is sourced from (Lewkowycz et al., 2022), while the PaLM result on MGSM is taken from (Chung et al., 2022). aMinerva (Lewkowycz et al., 2022), bGPT-4 (OpenAI, 2023b), cFlan-PaLM (Chung et al., 2022).
表格7:在链式思考提示(Wei et al.,2022)/自一致性(Wang et al.,2023)下对MATH、GSM8K和MGSM进行评估的结果。MATH上的PaLM结果来自于(Lewkowycz et al.,2022),而MGSM上的PaLM结果取自于(Chung et al.,2022)。aMinerva(Lewkowycz et al.,2022),bGPT-4(OpenAI,2023b),cFlan-PaLM(Chung et al.,2022)。
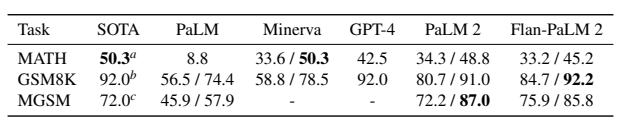
Table 8: Results on coding evaluations from the PaLM and PaLM 2-S* models. The PaLM 2-S* model is a version of the PaLM 2-S model trained with additional code-related tokens, similar to PaLM-540B-Coder. aPaLM (Chowdhery et al., 2022).
表8:PaLM和PaLM 2-S* 模型的编码评估结果。PaLM 2-S* 模型是PaLM 2-S模型的一个版本,使用额外的与代码相关的标记进行训练,类似于PaLM-540B-Coder。aPaLM(Chowdhery等,2022年)。

4.4 Coding 编码
Code language models are among the most economically significant and widely-deployed LLMs today; code LMs are deployed in diverse developer tooling (Github, 2021; Tabachnyk & Nikolov, 2022), as personal programming assistants (OpenAI, 2022; Hsiao & Collins, 2023; Replit, 2022), and as competent tool-using agents (OpenAI, 2023a).
代码语言模型是当前经济上最显著和广泛应用的LLM之一;代码LM被部署在多种开发者工具(Github,2021;Tabachnyk&Nikolov,2022),作为个人编程助手(OpenAI,2022;Hsiao&Collins,2023;Replit,2022)和能够使用工具的代理(OpenAI,2023a)中。
For low-latency, high-throughput deployment in developer workflows, we built a small, coding-specific PaLM 2 model by continuing to train the PaLM 2-S model on an extended, code-heavy, heavily multilingual data mixture.
为了在开发人员工作流中实现低延迟、高吞吐量的部署,我们在一个扩展的、代码密集、多语种混合数据上继续训练PaLM 2-S模型,构建了一个小型的、编码特定的PaLM 2模型。
We call the resulting model PaLM 2-S* which shows significant improvement on code tasks while preserving the performance on natural language tasks.
我们称之为PaLM 2-S*,它在代码任务的表现上显示出显著的改进,在自然语言任务上保持了良好的表现。
We evaluate PaLM 2-S*’s coding ability on a set of few-shot coding tasks, including HumanEval (Chen et al., 2021), MBPP (Austin et al., 2021), and ARCADE (Yin et al., 2022). We also test PaLM 2-S*’s multilingual coding ability using a version of HumanEval translated into a variety of lower-resource languages (Orlanski et al., 2023).
我们通过对一组few-shot编码任务进行PaLM 2-S* 的编码能力评估,包括HumanEval(Chen等人,2021)、MBPP(Austin等人,2021)和ARCADE(Yin等人,2022)。我们还使用一种翻译成各种低资源语言的版本的HumanEval来测试PaLM 2-S_的多语言编码能力(Orlanski等人,2023)。
Code Generation 代码生成
We benchmark PaLM 2 on 3 coding datasets: HumanEval (Chen et al., 2021), MBPP (Austin et al., 2021), and ARCADE (Yin et al., 2022).
我们在三个编码数据集上对PaLM 2进行基准测试:HumanEval(Chen等人,2021年),MBPP(Austin等人,2021年)和ARCADE(Yin等人,2022年)。
HumanEval and MBPP are natural language to code datasets which test the model’s ability to generate self-contained Python programs that pass a set of held-out test cases.
HumanEval和MBPP是自然语言到代码数据集,测试模型生成自包含Python程序的能力,这些程序通过一组保留的测试用例。
ARCADE is a Jupyter Notebook completion task that requires the model to complete the next cell in a notebook given a textual description and the preceding notebook cells.
ARCADE是一个Jupyter笔记本完成任务,要求模型在给定文本描述和前面的笔记本单元格的情况下完成笔记本的下一个单元格。
As in (Chen et al., 2021; Austin et al., 2021; Yin et al., 2022), we benchmark models in a pass@1 and pass@k setting.
与(Chen等人,2021年;Austin等人,2021年;Yin等人,2022年)一样,我们在pass@1和pass@k的情况下对模型进行基准测试。
We use greedy sampling for all pass@1 evals and temperature 0.8 with nucleus sampling p= 0.95 for all pass@k evals.
我们为所有pass@1 evals使用贪婪采样,对于所有pass@k evals,我们使用温度0.8的核心采样p = 0.95。
All samples are executed in a code sandbox with access to a small number of relevant modules and careful isolation from the system environment. For ARCADE, we use the New Tasks split containing problems from newly curated notebooks to avoid evaluation data leakage.
所有样本都在代码沙盒中执行,可以访问一些相关模块,并仔细隔离系统环境。对于ARCADE,我们使用新任务拆分,其中包含新收集的笔记本中的问题,以避免出现评估数据泄漏。
Multilingual Evaluation 多语言评估
We also evaluate PaLM 2-S*’s multilingual coding abilities using BabelCode (Orlanski et al., 2023) which translates HumanEval into a variety of other programming languages, including high-resource languages like C++, Java, and Go and low-resource languages like Haskell and Julia.
我们还使用BabelCode(Orlanski等,2023年)评估PaLM 2-S * 的多语言编码能力,该工具将HumanEval翻译成多种其他编程语言,包括高资源语言(如C ++、Java和Go)和低资源语言(如Haskell和Julia)。
The PaLM 2 code training data is significantly more multilingual than PaLM’s, which we hope yields significant gains on coding evals. Figure 6 shows PaLM 2-S*’s results compared to the original PaLM models. We show an example of multilingual program generation in Figure 7.
与PaLM相比,PaLM 2的代码训练数据涵盖了更多多语言内容,我们期望这会在编码评估上带来显著的提升。图6展示了PaLM 2-S* 与原始PaLM模型的结果比较。我们在图7中展示了多语言程序生成的示例。
PaLM 2-S* outperforms PaLM on all but two languages, with surprisingly little degradation on low-resource languages like Julia and Haskell; for instance PaLM 2-S* improves upon the much larger PaLM-Coder-540B by 6.3× on Haskell and on Julia by 4.7×.
PaLM 2-S* 在除两种语言之外的所有语言上表现优于 PaLM,而在像 Julia 和 Haskell 这样的低资源语言上却出人意料地没有太大的降级。
Remarkably, Java, JavaScript and TypeScript performance is actually higher than Python, the original language.
例如,PaLM 2-S* 在 Haskell 上比更大的 PaLM-Coder-540B 提高了 6.3 倍,在 Julia 上则提高了 4.7 倍。显著的是,Java、JavaScript 和 TypeScript 的性能实际上比原始语言 Python 更高。
4.5 翻译
An explicit design choice of PaLM 2 is an improved translation capability.
PaLM 2 的一个显式设计选择是改进翻译能力。
In this section, we evaluate sentence-level translation quality using recommended practices for high-quality machine translation (Vilar et al., 2022), and measure potential misgendering harms from translation errors.
在本节中,我们使用推荐的高质量机器翻译实践(Vilar等人,2022)评估句子级别的翻译质量,并测量翻译错误可能导致的性别歧视危害。
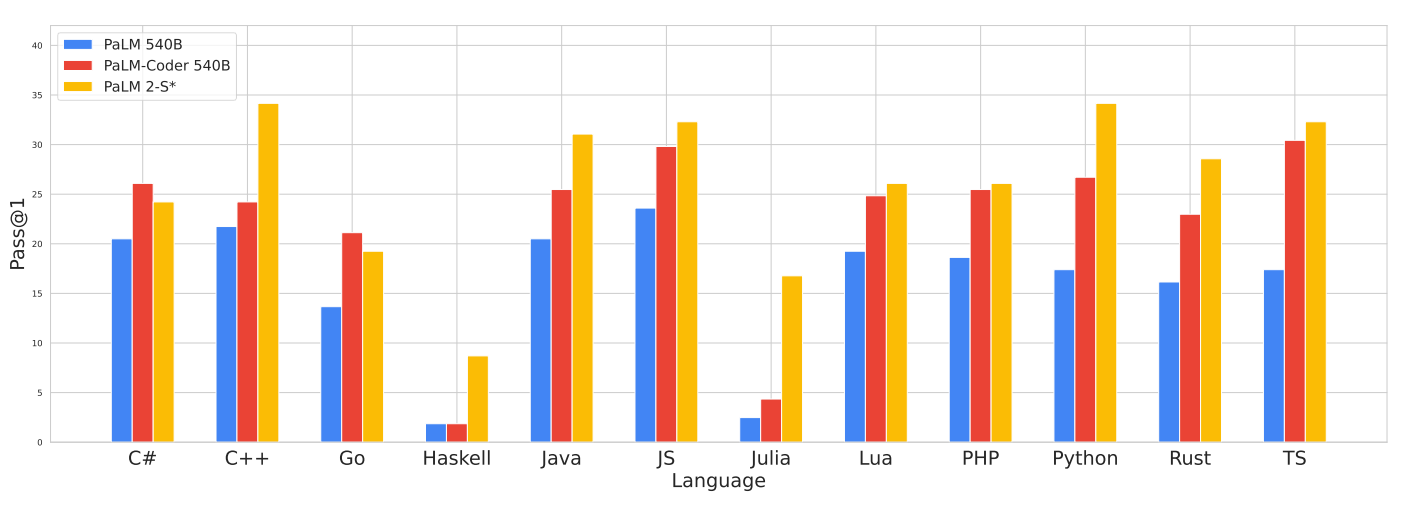
Figure 6: BabelCode-HumanEval results on 12 programming languages in the pass@1 setting.
在这一节中,我们使用高质量机器翻译的推荐实践(Vilar等,2022),评估句子级翻译质量,并在 pass@1 设置下测量图 6 中的 BabelCode-HumanEval 结果。
The Python results are not directly comparable to standard HumanEval due to differences in the evaluation procedure. Raw numeric results are shown in Table 18.
由于评估程序的差异,Python 的结果与标准的 HumanEval 不直接可比。原始数字结果如表 18 所示。
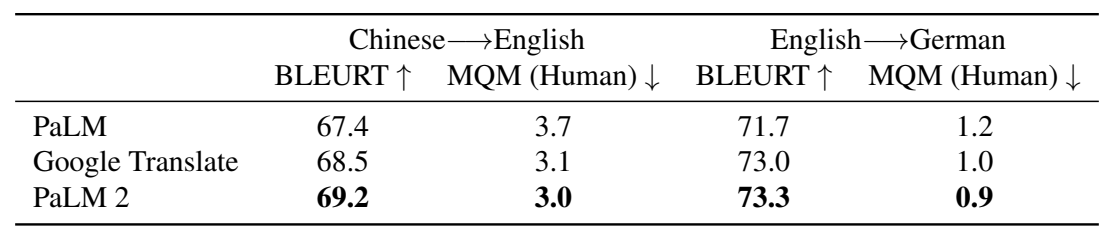
Table 9: Results on WMT21 translation sets. We observe improvement over both PaLM and the Google Translate production system according to our primary metric: MQM human evaluations by professional translators.
表格9:WMT21翻译数据集上的结果。我们观察到我们的主要指标——由专业翻译人员进行的MQM人工评估方面,相对于PaLM和Google翻译生产系统都有所改善。
WMT21 Experimental Setup WMT21实验设置
We use the recent WMT 2021 sets (Akhbardeh et al., 2021) to guard against train/test data leakage, and to facilitate comparison with the state of the art. We compare PaLM 2 against PaLM and Google Translate. For PaLM and PaLM 2, we prompt the model with 5-shot exemplars; for Google Translate, we send the source text directly to the model, as this is the format it expects.
我们使用最近的WMT 2021数据集(Akhbardeh等人,2021)来防止训练/测试数据泄露,并便于与现有技术进行比较。我们将PaLM 2与PaLM和Google Translate进行比较。对于PaLM和PaLM 2,我们使用5-shot样例提示模型;对于Google Translate,我们直接将源文本发送到模型,因为这是它预期的格式。
We use two metrics for evaluation:
我们使用两个度量标准进行评估:
-
BLEURT (Sellam et al., 2020): We use BLEURT9(Sellam et al., 2020) as a SOTA automatic metric instead of BLEU (Papineni et al., 2002) due to BLEU’s poor correlation with humanj udgements of quality, especially for high-quality translations (Freitag et al., 2022).
BLEURT(Sellam等人,2020年):我们使用BLEURT9(Sellam等人,2020年)作为SOTA自动指标,而不是BLEU(Papineni等人,2002年),因为BLEU与人类对于质量的判断之间的相关性较差,特别是对于高质量的翻译(Freitag等人,2022年)。 -
MQM (Freitag et al., 2021): To compute Multidimensional Quality Metrics (MQM), we hired professional translators (7 for English-to-German, 4 for Chinese-to-English) and measured translation quality with a document context version of MQM that mimics the setup proposed in Freitag et al. (2021), which includes the same error categories, severity levels and error weighting schema. Following Freitag et al. (2021), we assign the following weights: 5 for each major error, 1 for each minor error, and 0.1 for minor punctuation errors. The final system-level score is an average over scores from all annotations.
MQM(Freitag et al.,2021):为了计算多维质量指标(MQM),我们聘请了专业的翻译人员(7位英语-德语,4位中文-英语),并使用一份文件上下文版本的MQM来测量翻译质量,该版本模拟了Freitag et al.(2021)中提出的设置,包括相同的错误类别、严重性级别和错误加权模式。按照Freitag et al.(2021)的方法,我们分配以下权重:每个主要错误5分,每个次要错误1分,每个次要标点符号错误0.1分。最终的系统级评分是所有注释得分的平均值。
We present the results of an MQM study for Chinese-to-English and English-to-German in Table 9. MQM represents the average errors per segment, with lower numbers indicating better results. We observe that PaLM 2 improves quality both over PaLM and Google Translate.
我们在表9中呈现了汉语至英语和英语至德语的MQM研究结果。MQM表示每个段落的平均误差,数字越低表示结果越好。我们观察到PaLM 2在质量方面比PaLM和Google翻译都有所提升。
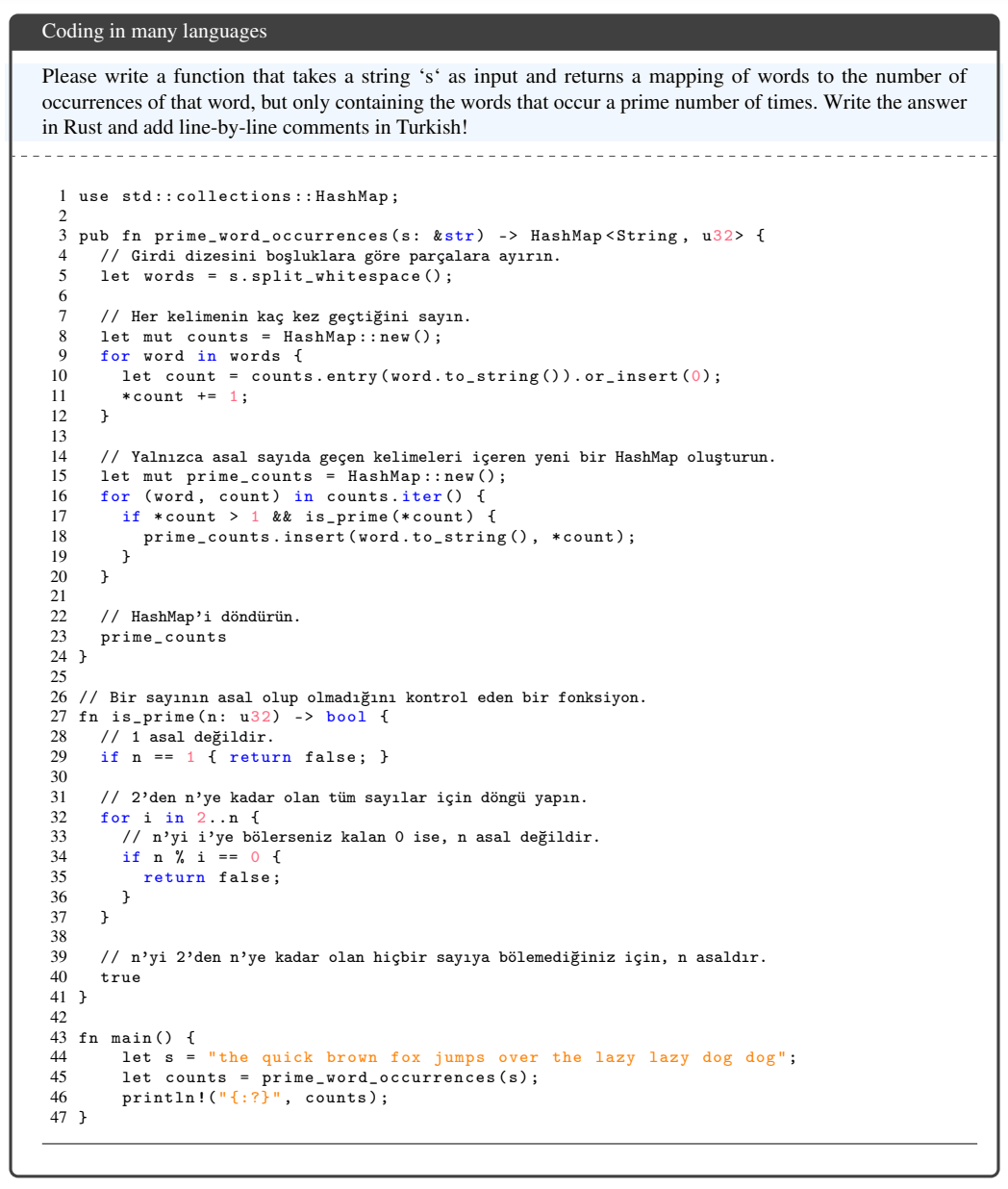
Figure 7: PaLM 2 can generate code and natural language across programming and natural languages.
图7:PaLM 2可以跨编程语言和自然语言生成代码和自然语言。
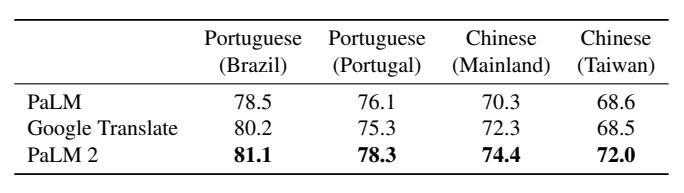
Table 10: Results on the FRMT (Few-shot Regional Machine Translation) benchmark of dialect-specific translation. Inputs are 5-shot exemplars and scores are computed with BLEURT.
表格10:方言特定翻译的FRMT(Few-shot Regional Machine Translation)基准测试结果。输入是5个样例,得分通过BLEURT计算。
Regional translation experimental setup 区域翻译实验设置
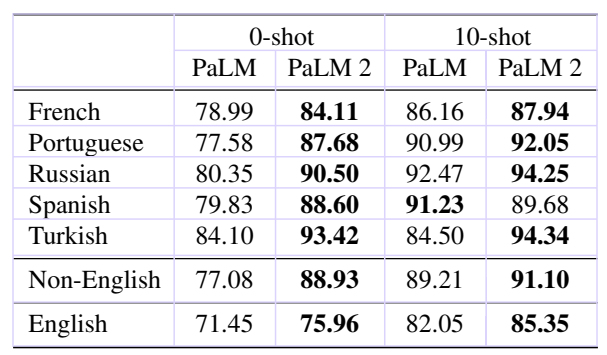
We also report results on the FRMT benchmark (Riley et al., 2023) for Few-shot Regional Machine Translation. By focusing on region-specific dialects, FRMT allows us to measure PaLM 2’s ability to produce translations that are most appropriate for each locale—translations that will feel natural to each community. We show the results in Table 10. We observe that PaLM 2 improves not only over PaLM but also over Google Translate in all locales.
我们还报道了在FRMT基准测试上的结果(Riley等人,2023年)。该测试是针对区域特定方言的少样本区域机器翻译。通过关注特定地区方言,FRMT允许我们衡量PaLM 2产生的翻译是否最适合每个地方,这些翻译将对每个社区来说都感觉自然。我们在表10中展示结果。我们观察到,PaLM 2不仅优于PaLM,而且在所有地区都优于谷歌翻译。
Potential misgendering harms We measure PaLM 2 on failures that can lead to potential misgendering harms in zero-shot translation. When translating into English, we find stable performance on PaLM 2 compared to PaLM, with small improvements on worst-case disaggregated performance across 26 languages. When translating out of English into 13 languages, we evaluate gender agreement and translation quality with human raters. Surprsingly, we find that even in the zero-shot setting PaLM 2 outperforms PaLM and Google Translate on gender agreement in three high-resource languages: Spanish, Polish and Portuguese. We observe lower gender agreement scores when translating into Telugu, Hindi and Arabic with PaLM 2 as compared to PaLM. See Appendix E.5 for results and analysis.
潜在性错性别伤害是我们衡量PaLM 2失败的指标,在零-shot翻译中可能导致潜在性错性别伤害的情况。当翻译成英语时,我们发现与PaLM相比,PaLM 2在PaLM 2上表现稳定,并且在26种语言中最差情况的分解效果有所改善。当从英语翻译成13种语言时,我们用人工评级评估性别一致性和翻译质量。令人惊讶的是,即使在零-shot设置中,PaLM 2在三种高资源语言(西班牙语、波兰语和葡萄牙语)的性别一致性方面仍然优于PaLM和谷歌翻译。我们发现在翻译成泰卢固语、印地语和阿拉伯语时,PaLM 2的性别一致性得分比PaLM低。有关结果和分析,请参见附录E.5。
4.6 自然语言生成
本文作者:Maeiee
本文链接:《PaLM 2 Technical Report》
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
